Generate Speech Using the AWS Polly SDK for Java
In this exercise, you will explore how to generate life-like speech using the Java SDK in a test application. The application presents a menu of options that you can use to test the application features. But before you run it, you need to complete the code.
- Download the source code bundle from PollyControl.zip and explode the zip file onto your filesystem.
- Open the Eclipse IDE and open the project from the filesystem by using the File | Open projects from filesystem… menu option.
- Most of the code is implemented for you. However, the ability for the app to render the words in time with the audio output needs to be implemented. What is missing is a call to Amazon Polly via the SDK, to retrieve the speech marks.
A ‘dummy’ implementation has been put in place for you in the /PollyControl/src/main/java/idevelop/samples/PollyManager.javafile, in the GetSpeechMarkers() method. The dummy implementation constructs a result object as if it were returned from the Polly service when calling synthesizeSpeech():
String dummySpeechMarks = "{\"time\":1,\"type\":\"word\",\"start\":0,\"end\":100,\"value\":\"You need to implement the call to SynthesizeSpeechRequest() in GetSpeechMarkers()\"}\n";
InputStream dummyStream = new ByteArrayInputStream(
dummySpeechMarks.getBytes(StandardCharsets.UTF_8.name())
);
SynthesizeSpeechResult synthRes = new SynthesizeSpeechResult().withAudioStream(dummyStream);
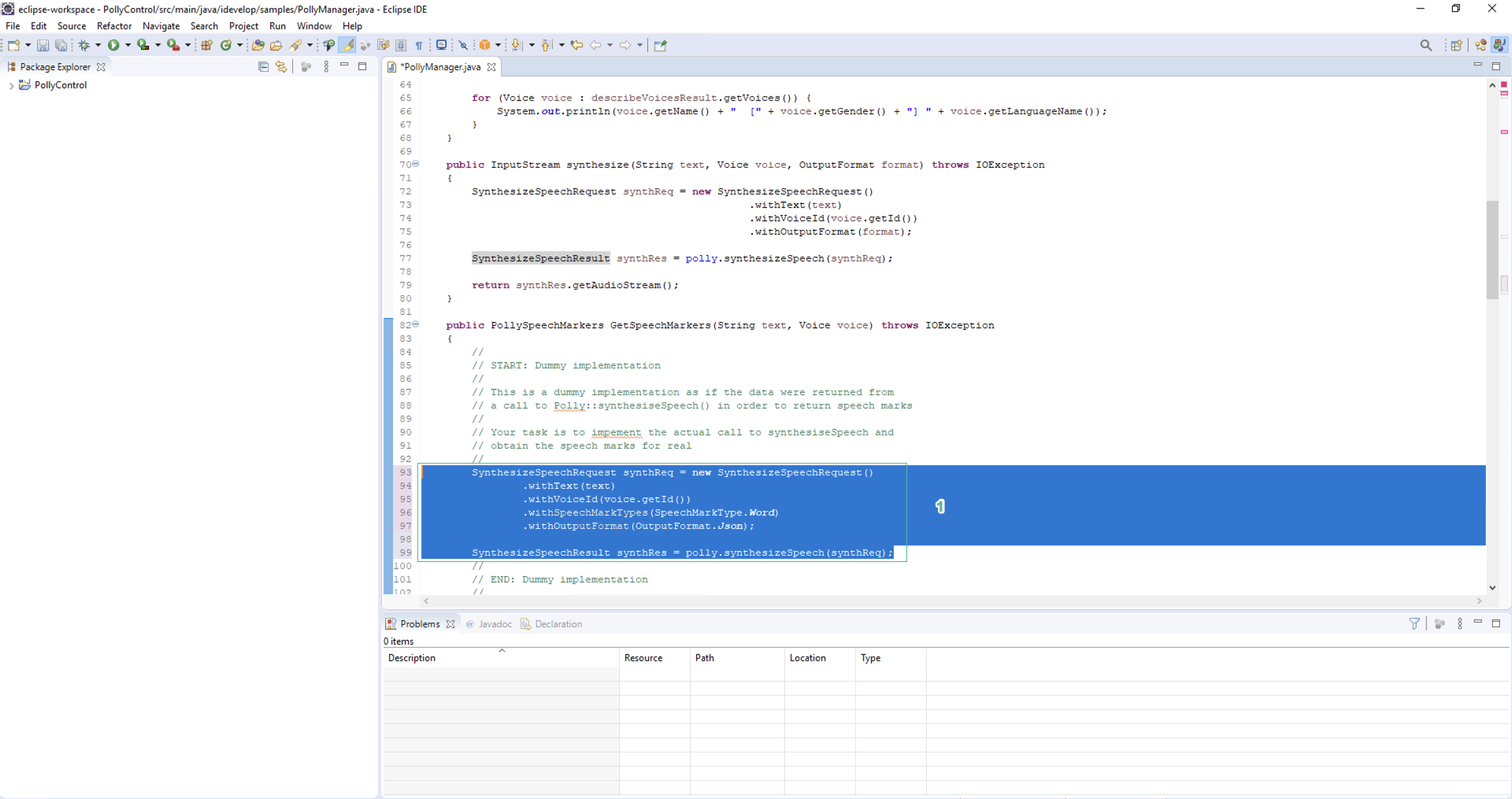
You need to remove this code, and instead, replace it with code that actually calls the Amazon Polly service to obtain speech marks.
- Run the application. You will see a menu like this:
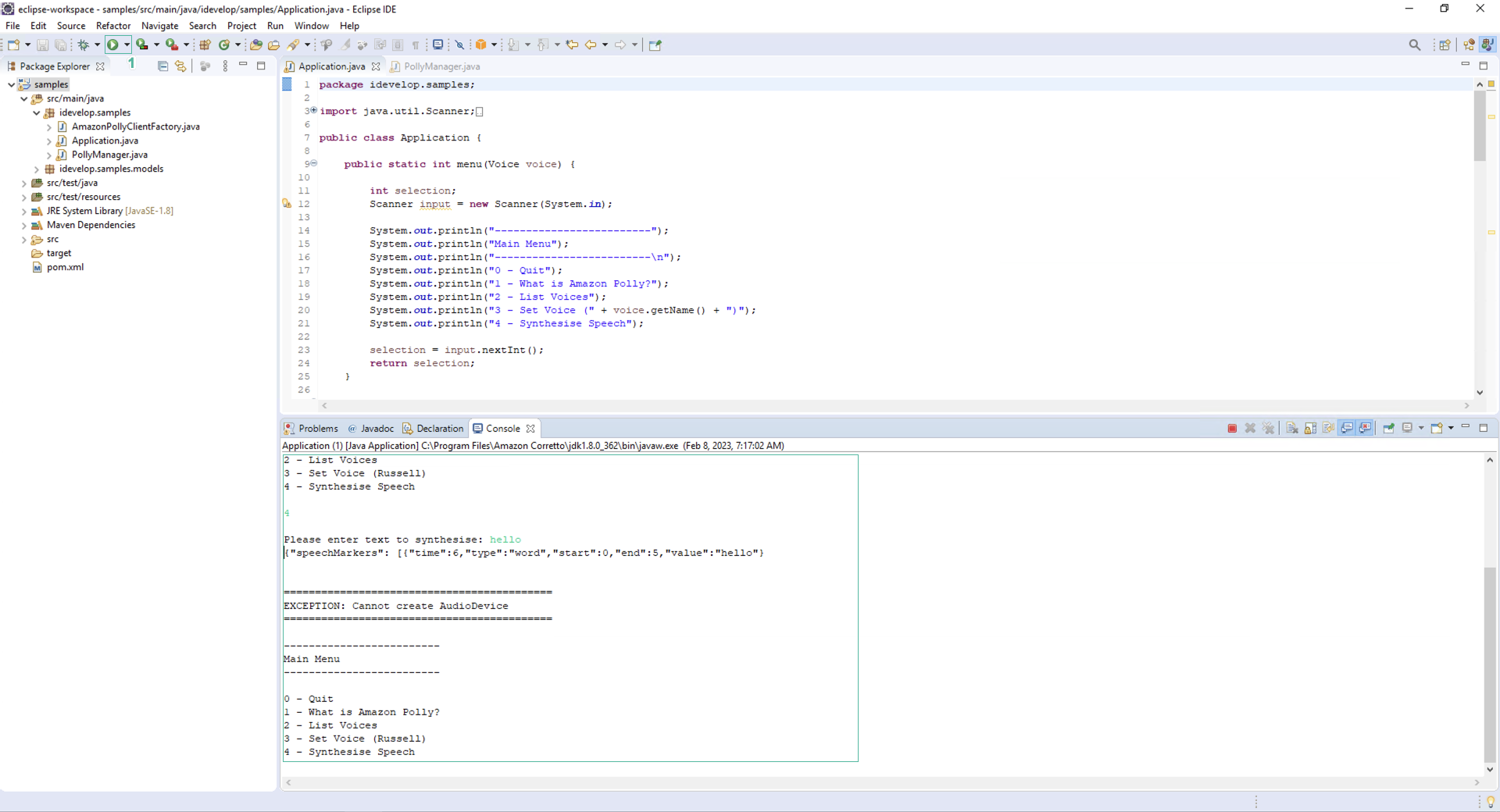
Try running each of the menu options, and notice that as speech is rendered, the matching text is displayed in time with the audio. This is accomplished by the application first requesting the speech markers from Amazon Polly, and then requesting the audio rendering. As the audio is played, a background thread keeps track of the position of the audio being replayed, and uses the speech marks data to display the correct word in time with the audio.
Spend a few moments looking through the code so you can see how this is accomplished