Generate Speech Marks By AWS CLI
Speech marks are metadata that describe the speech that you synthesize, such as where a sentence or word starts and ends in the audio stream. When you request speech marks for your text, Amazon Polly returns this metadata instead of synthesized speech. By using speech marks in conjunction with the synthesized speech audio stream, you can provide your applications with an enhanced visual experience.
- Right click and download the test.json file.
- Right click and download the.
Remember to change the command to your profile and region
aws polly synthesize-speech --region ap-southeast-2 --output-format json --voice-id Russell --speech-mark-types "viseme" "word" --text "Text to say" test.json --profile aws-lab-env; cat test.json
The terminal output will be similar to this:
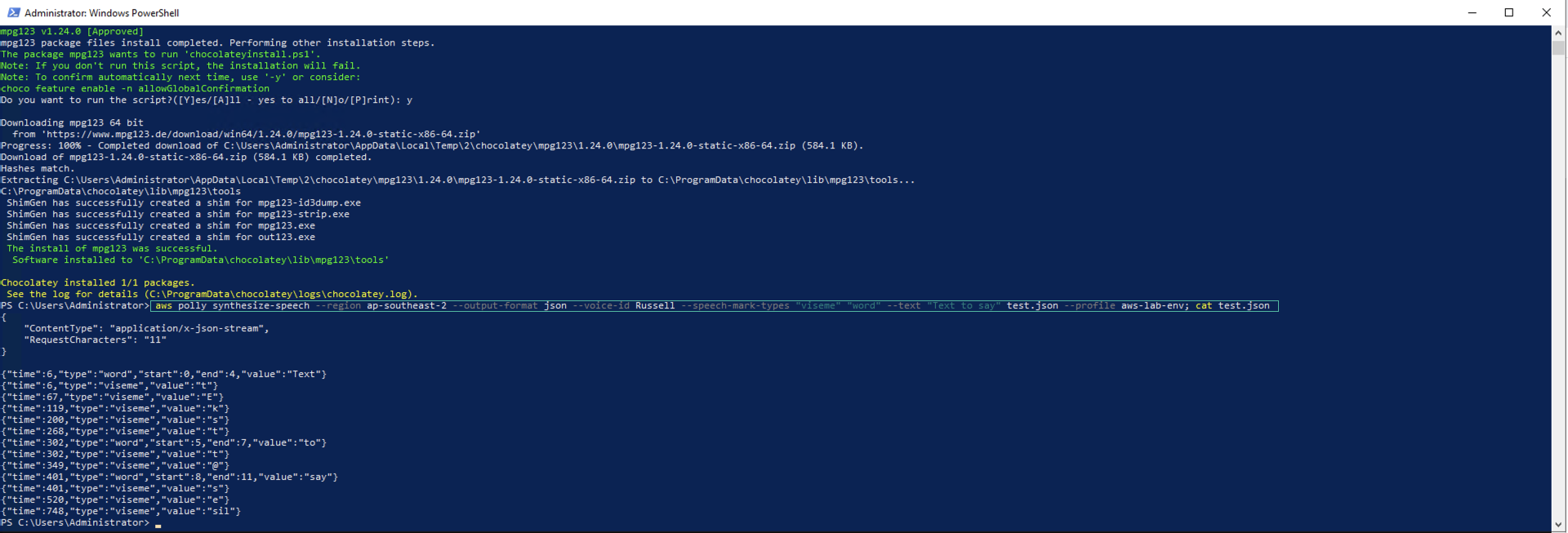
The speech marks returned provide you with the start and end points of the various words and visemes in the text that has been synthesised.
- Experiment with the input text to convert, to see how the speech marks change to match. In the next exercise, you will use these speech marks to render the words in time with the synthesised speech.