Tạo speech marks bằng AWS CLI
Speech mark là metadata mô tả giọng nói mà bạn tổng hợp, chẳng hạn như vị trí bắt đầu và kết thúc của một câu hoặc từ trong luồng âm thanh. Khi bạn yêu cầu speech mark, Amazon Polly sẽ trả lại metadata thay vì giọng nói được tổng hợp. Bằng cách sử dụng speech mark kết hợp với speech audio stream được tổng hợp, bạn có thể cung cấp cho ứng dụng của bạn những trải nghiệm nâng cao hơn.
- Tải tập tin test.json
- Trong của sổ terminal, thực thi lệnh sau:
aws polly synthesize-speech --region <YOUR-REGION> --output-format json --voice-id Russell --speech-mark-types "viseme" "word" --text "Text to say" test.json --profile aws-lab-env; cat test.json
Thay <YOUR_REGION> bằng region mà bạn đang sử dụng.
Kết quả trả về như sau:
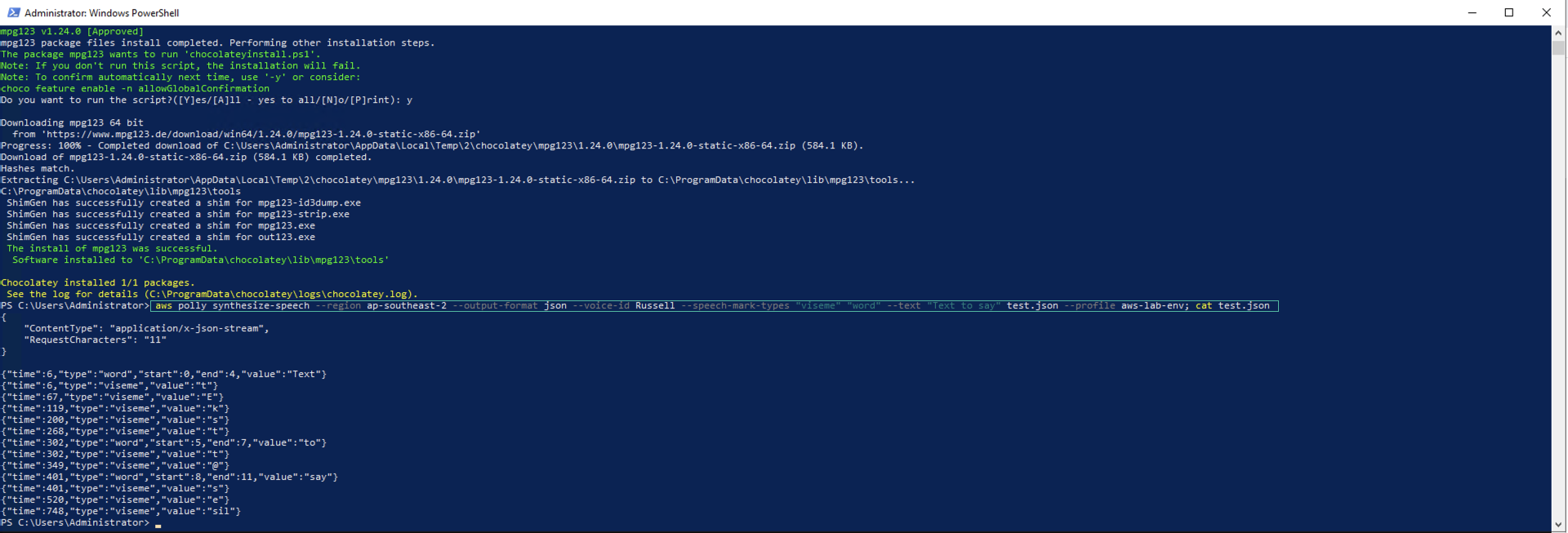
Speech marks trả về cung cấp cho bạn điểm bắt đầu và kết thúc của các từ và visemes trong đoạn văn được tổng hợp.
- Thử thay đổi đoạn văn đầu vào và xem cách speech marks thay đổi đoạn văn như thế nào. Trong bài tập tới, bạn sê sử dụng speech marks để biểu diễn các từ trong thời gian phù hợp.